
脳信号を“声”に変えるストリーミング技術――麻痺で声を失った人に自然な会話を再び
私たちが普段何気なく交わしている会話は、実は極めて高速でスムーズなやりとりです。しかし、病気や事故で話すことができなくなった人たちにとって、「伝える」ことはとても大きな課題です。視線や文字入力を使った支援機器では、1分間に数語しか伝えられないことも珍しくありません。これは会話のテンポを大きく崩し、コミュニケーションに不自由さを感じる原因になります。
こうした課題に対し、脳の活動から直接言葉を生み出す「ブレイン・コンピュータ・インターフェース(Brain Computer Interface, BCI)」という技術が注目されています。特に、脳の信号をもとに声そのものを再現する「スピーチ・ニューロプロステーシス(speech neuroprosthesis)」は、日常会話を取り戻す手段として期待が高まっています。
研究の概要:脳信号からリアルタイムで音声を合成
2025年4月、カリフォルニア大学バークレー校とサンフランシスコ校の研究チームは、重度の発話障害を持つ女性の脳信号をもとに、彼女の「かつての声」でリアルタイムに音声を合成する技術を発表しました。この技術は、脳の信号を読み取り、AIがリアルタイムで解読し、スピーカーから声が発せられる仕組みです。
この技術は、「考えた言葉」を脳の信号としてとらえ、そこから音声を生成します。特徴的なのは、以前録音された本人の声を使い、まさに「その人らしい声」で話せるようにした点です。これは単なる情報伝達以上に、本人にとっての大きな安心感や自己表現につながります。
技術の仕組み:ECoGとAIでかつての声を再現
この技術は大きく分けて以下に紹介する3つのステップによって実現されました。
1. 脳からの信号を取得

出典:UC Berkeley Engineering, Brain-to-voice neuroprosthesis restores naturalistic speech
研究チームはまず、脳幹卒中により、声を一切出せない重度の発話麻痺を抱える被験者の頭に脳の表面を流れる電気信号であるECoG(Electrocorticogra)を計測する装置を埋め込みました。本実験で用いられた装置は253の微小な電極から構成されています。
この電極は発話を司る脳の部位(感覚運動野)の表面に配置され、被験者が「話そう」と頭で指令を出した瞬間の微弱な脳信号をリアルタイムに記録します。ECoGは、頭皮上から計測するEEG(脳波)よりノイズが少なく高精度な信号が得られるため、BCI研究で期待される手法です。
2. AIが解読
次に、この膨大な脳信号データを音声に翻訳するAIを構築します。ここで活躍するのがRNN-T(Recurrent Neural Network Transducer)という深層学習モデルです。RNN-Tはもともと音声認識で用いられる技術で、音声波形に代表される時系列データの入力から対応する文字列をリアルタイムに出力するのに適しています。
モデルを学習させるためのデータを集めるために、被験者にコンピュータ画面に表示された文章を頭の中で発声してもらい、その際に発声する脳内の電気信号を記録するというプロセスを累計23000回以上行いました。このトレーニングにより、モデルは「特定の脳信号パターンが現れたら特定の単語(文字列)が意図されている」という対応関係を学習していきます。
3. 声を合成
研究者たちは、被験者が発話麻痺を抱える前のホームビデオ音声などを集めて、個人別のテキスト読み上げモデルを作成しました。そして前述のRNN-Tが解読した「テキスト」に、この本人の声の読み上げAIを適用することで、最終的にスピーカーから流れる音声が被験者本人の声色になるよう工夫したのです。
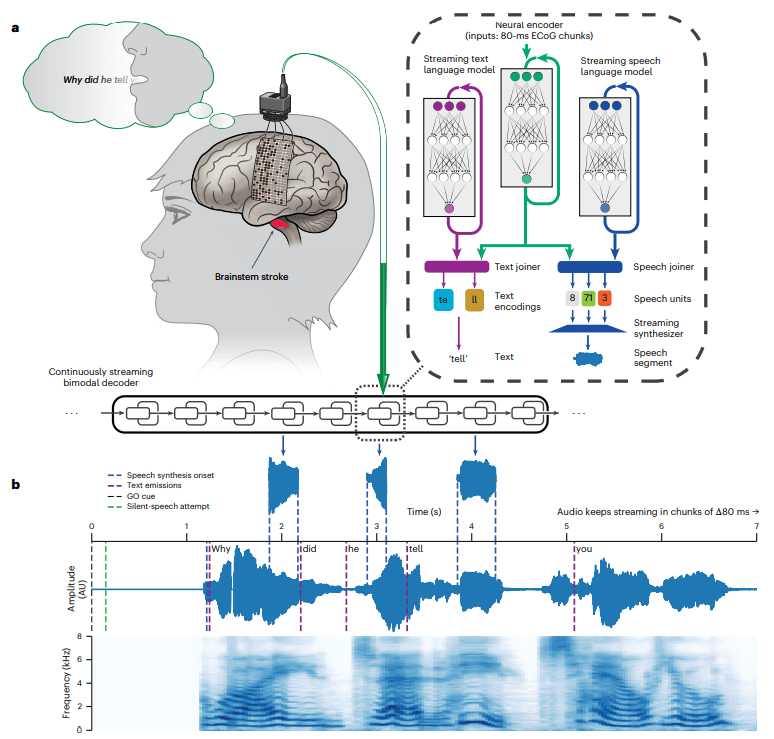
出典:Littlejohn KT, Cho CJ, Liu JR, Silva AB, Yu B, Anderson VR, Kurtz-Miott CM, Brosler S, Kashyap AP, Hallinan IP, Shah A, Tu-Chan A, Ganguly K, Moses DA, Chang EF, Anumanchipalli GK. A streaming brain-to-voice neuroprosthesis to restore naturalistic communication. Nat Neurosci. 2025 Apr;28(4):902-912. doi: 10.1038/s41593-025-01905-6. Epub 2025 Mar 31. PMID: 40164740.
実験結果:速さと正確さに驚きの進化
実験の結果、このシステムはハイスピードで低遅延かつ滑らかな発話を再現できることが示されました。特に注目すべき数字は「毎分の単語数(WPM)」です。被験者は1,000語以上の大語彙セットにおいて毎分47.5語のペースで音声を出力できました。さらに、介護生活における会話で頻出する50語程度に語彙を絞れば毎分90.9語に達し、これは人間の普通の会話スピード(毎分約130語)に迫る水準です。以前1の音声解読BCI記録であった毎分15語・50語彙という値と比べると、新手法の高速ぶりが際立ちます。
また従来の発話支援BCIでは、ユーザが「発話しよう」と思ってから実際に音が出るまで数秒のラグがあるのが当たり前でした。しかしこのシステムでは、発話の脳信号の立ち上がりから1秒以内には最初の音がスピーカーから出始めることが確認されました。処理自体もほぼリアルタイムで進行し、システム全体として約0.3秒程度の遅れしか生じないとのことです。これは人間同士の会話で生じる一呼吸ほどの間隔に過ぎず、対話の自然さを損なわないレベルと言えるでしょう。
さらに、この解読モデルは訓練データにない新しい単語や文にも柔軟でした。学習時に登場しなかった語)を試しても、モデルはそれらを正しく発音できたのです。これはAIが単に訓練データを丸暗記したのではなく、言語の音の組み合わせ規則をきちんと学習している証拠だと考えられます。
おわりに ── 失われた声を取り戻す未来へ
この技術の一番の価値は、単に声を出せるようになるということではありません。「自分の意思をリアルタイムに伝えられる」ことで、会話のテンポが戻り、他者との関係も自然になります。そして何より、自分の声で話すことができるという経験は、自己表現や尊厳の回復にもつながると考えられます。
もし、話せなくなっても、再び「自分の声」で語りかけられる未来があるとしたら――。この技術は、そんな希望の第一歩となるかもしれません。
🧠 編集後記|BrainTech Magazineより
脳からの信号を読み取り、言葉として再構成する──かつて困難とされてきた課題に、非侵襲の手法で挑んだ今回の研究は、今後のBCI開発に向けた貴重な一歩となりました。まだ実用化には距離があるものの、これまで見えにくかった脳とテクノロジーの接点が、確かに輪郭を持ちはじめています。
📝 本記事で紹介した研究論文
Littlejohn KT, Cho CJ, Liu JR, Silva AB, Yu B, Anderson VR, Kurtz-Miott CM, Brosler S, Kashyap AP, Hallinan IP, Shah A, Tu-Chan A, Ganguly K, Moses DA, Chang EF, Anumanchipalli GK. A streaming brain-to-voice neuroprosthesis to restore naturalistic communication. Nat Neurosci. 2025 Apr;28(4):902-912. doi: 10.1038/s41593-025-01905-6. Epub 2025 Mar 31. PMID: 40164740.
- Moses DA, Metzger SL, Liu JR, Anumanchipalli GK, Makin JG, Sun PF, Chartier J, Dougherty ME, Liu PM, Abrams GM, Tu-Chan A, Ganguly K, Chang EF. Neuroprosthesis for Decoding Speech in a Paralyzed Person with Anarthria. N Engl J Med. 2021 Jul 15;385(3):217-227. doi: 10.1056/NEJMoa2027540. PMID: 34260835; PMCID: PMC8972947. ↩︎
WRITER

NeuroTech Magazine編集部
BrainTech Magazine編集部のアカウントです。
運営するVIE株式会社は、「Live Connected, Feel the Life~」をミッションに、ニューロテクノロジーとエンターテイメントで、感性に満ちた豊かな社会をつくることをサポートするプロダクトを創造することで、ウェルビーイングに貢献し、さらに、脳神経に関わる未来の医療ICT・デジタルセラピューティクスの発展にも寄与していきます。
一覧ページへ戻る